Anthropic Releases Claude Opus 4.7 With Cyber Safeguards

Anthropic Releases Claude Opus 4.7 With Cyber Safeguards
The new model is aimed at longer coding agents, higher-resolution vision, and requests that need more control over reasoning budget.
San Francisco - Anthropic made Claude Opus 4.7 generally available, saying the model improves on Opus 4.6 for advanced software engineering while adding real-time cyber safeguards meant to block prohibited or high-risk cybersecurity requests.
The release is not just a benchmark update. Anthropic is changing the control surface around its frontier model through effort levels, task budgets, higher-resolution image input, and classifier-based cyber gates.
The Story So Far
Anthropic has positioned the Opus line as its highest-capability Claude tier for complex work. The company said Opus 4.7 is available across Claude products, the Anthropic API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry.
"Our latest model, Claude Opus 4.7, is now generally available." - Anthropic announcement, May 3, 2026
The company kept the headline API price unchanged from Opus 4.6, at $5 per million input tokens and $25 per million output tokens. Anthropic's model documentation lists claude-opus-4-7 as the API alias and says the model supports a 1 million token context window, a 128,000 token maximum synchronous output, adaptive thinking, and a January 2026 reliable knowledge cutoff.
That package makes Opus 4.7 a direct enterprise and developer release, not a lab-only preview. Anthropic's system card still says a more powerful limited model, Claude Mythos Preview, sits above it.
What's Happening Now
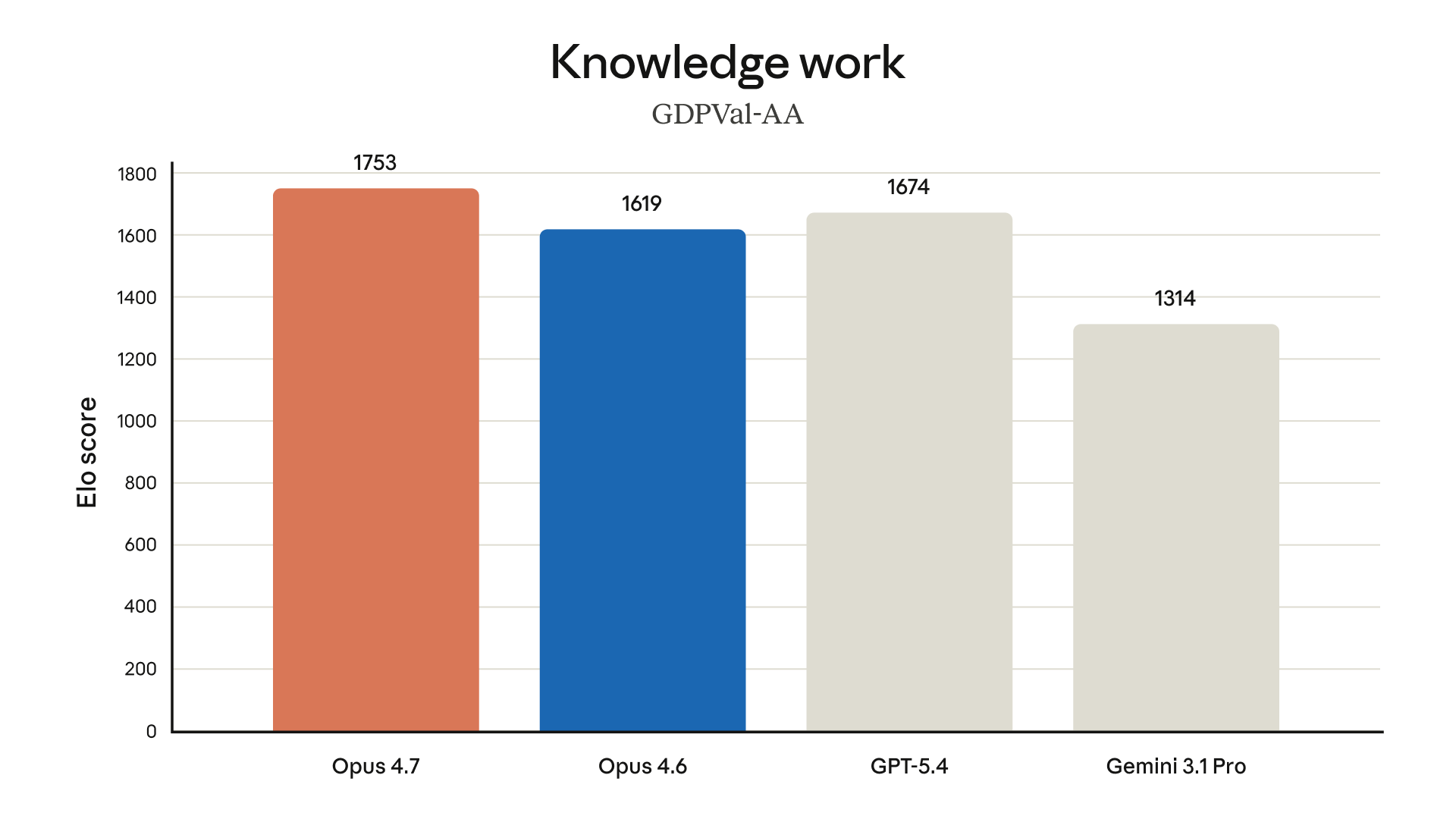
Anthropic says the largest gains are in advanced software engineering, especially difficult tasks that require longer runs. That means the model is being sold less as a chatbot that writes a snippet and more as an agent that plans, uses tools, checks errors, and keeps working.
The system card reports Opus 4.7 at 87.6% on SWE-bench Verified, compared with 80.8% for Opus 4.6. It also reports 64.3% on SWE-bench Pro, compared with 53.4% for Opus 4.6.
Those scores should be read as Anthropic's reported evaluations, not as a universal ranking of all coding work. The system card also reports 69.4% on Terminal-Bench 2.0 and notes that OpenAI used a specialized harness for its reported GPT-5.4 score, making that comparison inexact.
"Overall, the model shows superior capabilities to those of its predecessor, Claude Opus 4.6, but weaker capabilities than those of our most powerful model, Claude Mythos Preview." - Claude Opus 4.7 system card
The model also expands visual input. Anthropic says Opus 4.7 supports higher-resolution image processing up to 2,576 pixels on the long edge, or roughly 3.75 megapixels. That matters for agents reading dense screenshots, spreadsheets, diagrams, code review UIs, and documents where small visual details change the answer.
The Conservative View
The strongest pro-release argument is that U.S. companies need frontier coding and automation tools in the hands of developers, not locked in narrow research programs. Making Opus 4.7 broadly available through major U.S. cloud platforms gives enterprises a path to test agentic coding inside existing procurement and security systems.
The cyber controls also answer one common concern about frontier deployment. Anthropic says it is releasing the model with real-time safeguards designed to detect and block prohibited or high-risk cybersecurity use, while allowing ordinary defensive work by default.
"These safeguards are designed to automatically detect and block requests that may indicate prohibited or high-risk cybersecurity usage based on our Usage Policy." - Anthropic support page on real-time cyber safeguards
From this view, the model gives U.S. developers stronger automation while preserving a boundary around clearly dangerous cyber use. That matters for cloud competition, defense contractors, financial firms, and software companies that want stronger AI without a blanket ban on security work.
The Progressive View
The cautionary view starts with dual-use risk. A model that can run longer coding loops, use tools, and reason through software systems can also help with harmful cyber tasks if controls fail or attackers find workarounds.
Anthropic's system card says Opus 4.7 is roughly similar to Opus 4.6 in cyber capabilities and weaker than Mythos Preview. It also says testing by the UK AI Security Institute found Opus 4.7 could not fully solve a simulated corporate-network cyber range, though its best attempt completed steps estimated at about five hours of human cyber-expert work while the full range was estimated above 10 hours.
"Cyber evaluations. Opus 4.7 is roughly similar to Opus 4.6 in cyber capabilities." - Claude Opus 4.7 system card
That result supports neither panic nor complacency. It says the model did not cross the full simulated range, but it did complete enough work to justify real safeguards, monitoring, and disclosure about limitations.
Other Perspectives
Security professionals will care about false positives. Anthropic says ordinary dual-use work such as vulnerability detection is not blocked by default, but defensive researchers whose legitimate work is affected can apply through the Cyber Verification Program. The support page says Bedrock and Vertex AI users are not currently eligible for that program.
Enterprise developers will care about cost behavior. The headline price stayed the same, but Anthropic says Opus 4.7 uses an updated tokenizer, meaning the same input can map to roughly 1.0 to 1.35 times as many tokens depending on content type. A team running long agentic coding jobs could see cost changes even without a listed price increase.
Cloud platforms will care because availability through Bedrock, Vertex AI, and Microsoft Foundry immediately puts the model into large enterprise AI channels. That reduces friction for companies that already buy AI through those platforms instead of direct lab accounts.
Technical Explainer: What Actually Changed
Agentic coding differs from chatbot coding because the model is not just answering one prompt. It breaks a task into steps, edits files, runs tests, reads failures, revises, and continues until it reaches a stopping condition.
Effort controls change how much reasoning budget the model spends. Anthropic says Opus 4.7 adds an xhigh effort level between high and max, giving developers a middle option when a task needs more depth but not the largest possible spend.
Task budgets are a second control. They let developers guide token spending across longer runs so the model does not burn too much budget early, then stall when the hard part arrives.
Higher-resolution vision is the third piece. A coding agent that can read small UI elements, charts, tables, and stack traces from screenshots can work across more real enterprise workflows than a text-only assistant.
The cyber safeguards are the fourth piece. They are classifier-driven gates around requests, intended to distinguish prohibited activity, high-risk dual-use activity, and ordinary defensive security work.
Economic Implications
The direct cost signal is mixed. Anthropic did not raise the listed Opus price, but the updated tokenizer and higher effort levels can change effective cost per task. For companies, the relevant bill is not the price per million tokens alone, it is the total token spend needed to finish a coding run.
The productivity claim is larger than the pricing claim. If Opus 4.7 can finish more difficult software tasks without a human restarting the loop, companies can shift developer time from routine debugging to review, architecture, and product decisions. That benefit depends on actual pass rates in a company's codebase, not just public benchmarks.
The strategic implication is that U.S. AI labs are still competing on agentic software work while trying to formalize cyber-risk controls. The model's release through Amazon, Google, and Microsoft cloud channels also ties frontier AI competition directly to U.S. enterprise infrastructure.
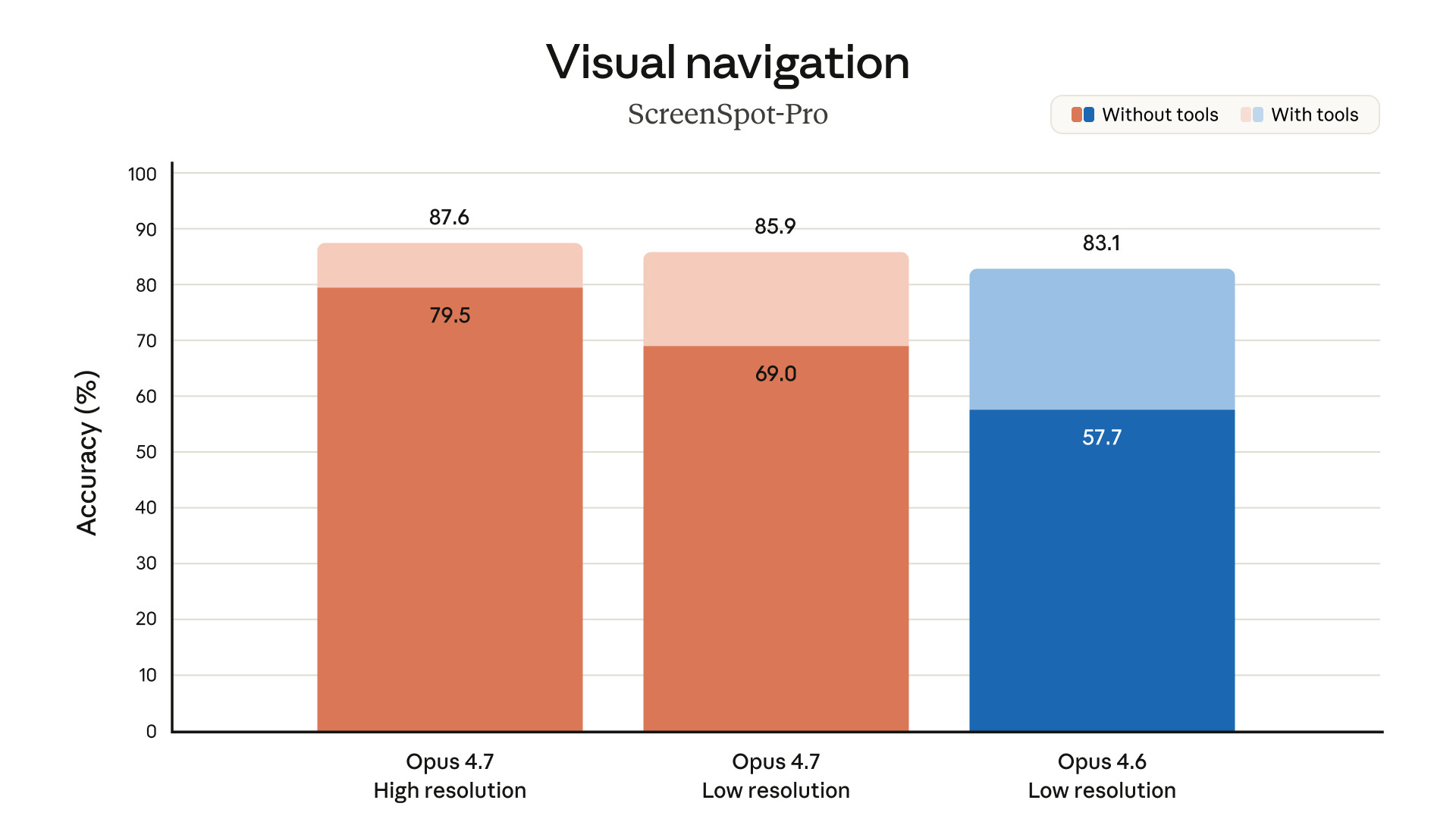 Image via Anthropic (fair use, official company image)
Image via Anthropic (fair use, official company image)
By the Numbers
Anthropic reports Opus 4.7 at 87.6% on SWE-bench Verified, compared with 80.8% for Opus 4.6.
Anthropic reports Opus 4.7 at 64.3% on SWE-bench Pro, compared with 53.4% for Opus 4.6.
The company lists a 1 million token context window and a 128,000 token maximum synchronous output in its model documentation.
Anthropic priced Opus 4.7 at $5 per million input tokens and $25 per million output tokens, the same headline price as Opus 4.6.
What People Are Saying
"Our latest model, Claude Opus 4.7, is now generally available." - Anthropic announcement, May 3, 2026
"Overall, the model shows superior capabilities to those of its predecessor, Claude Opus 4.6, but weaker capabilities than those of our most powerful model, Claude Mythos Preview." - Claude Opus 4.7 system card
"Cyber evaluations. Opus 4.7 is roughly similar to Opus 4.6 in cyber capabilities." - Claude Opus 4.7 system card
"These safeguards are designed to automatically detect and block requests that may indicate prohibited or high-risk cybersecurity usage based on our Usage Policy." - Anthropic support page on real-time cyber safeguards
The Big Picture
Opus 4.7 is a broader release of agentic capability, not simply a faster model name. Anthropic is pairing stronger coding performance with more knobs for developers and more restrictions around cyber misuse.
The next test is operational. Enterprises will measure whether the model completes real software tasks at an acceptable cost, while security teams will test whether the cyber safeguards block harmful requests without blocking legitimate defensive work.