U.S. Evaluators Say DeepSeek V4 Trails AI Frontier By Eight Months

Federal testers say the Chinese open-weight model is cheaper than comparable U.S. models on most tested tasks, but weaker on held-out reasoning and agent benchmarks.
GAITHERSBURG, Maryland - The Commerce Department's AI evaluation center said DeepSeek V4 Pro is the strongest Chinese model it has tested, but still trails leading U.S. frontier models by about eight months on the government's aggregate benchmark suite.
The May 1 evaluation by the National Institute of Standards and Technology's Center for AI Standards and Innovation gives U.S. policymakers a rare primary-source look at the AI race with China. CAISI said the model looks closer to the U.S. frontier on DeepSeek's own published benchmark set, but falls back when tested against a pre-committed suite that includes held-out software, cyber and abstract-reasoning tasks.
Why It Matters
The finding cuts in two directions. CAISI said DeepSeek V4 does not match the leading U.S. systems in aggregate capability, according to a model that compares performance across cyber, software engineering, science, abstract reasoning and math.
At the same time, CAISI said DeepSeek V4 costs less than GPT-5.4 mini on five of seven benchmark comparisons. That matters because capability and deployment economics are different strategic questions. A model can lag the frontier and still matter if its price lets more users run more tasks.
The evaluation also tests a central policy claim in the AI competition: public benchmark scores do not always capture what a model can do in harder, less exposed settings. CAISI said its suite included non-public or held-out tests, including ARC-AGI-2's semi-private dataset and CAISI's internally built PortBench software-engineering evaluation.
The Story So Far
CAISI said it evaluated the open-weight DeepSeek V4 Pro model in April 2026. The agency described the model as an open-weight system, which means users can access model weights rather than only sending prompts through a hosted API. Open-weight release can make independent testing easier, but it also changes the deployment and security discussion because the model can be run outside the developer's own service.
The center's mandate is broader than one lab or one model. NIST says CAISI will lead evaluations of U.S. and adversary AI systems, foreign AI adoption and the state of international AI competition. NIST also says the center will examine risks such as cybersecurity, biosecurity and chemical weapons, and coordinate with agencies including the Department of Defense, Department of Energy, Department of Homeland Security, the Office of Science and Technology Policy and the intelligence community.
The White House AI Action Plan lists frontier model risk evaluation under its international security pillar. The plan calls for the government to ensure that it is at the front of evaluating national-security risks in frontier models, while also encouraging open-source and open-weight AI under its innovation pillar.
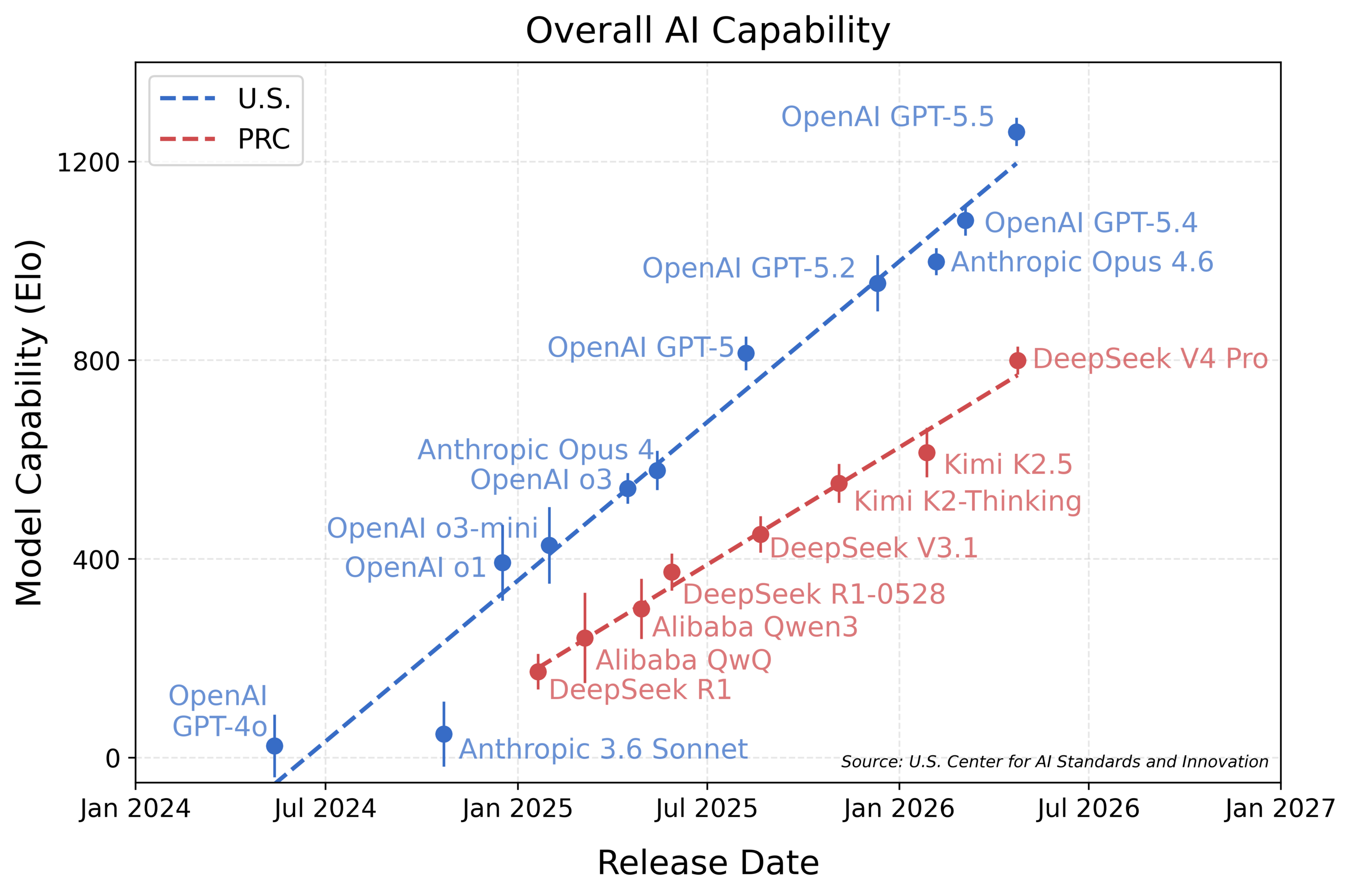 Chart by National Institute of Standards and Technology (public domain)
Chart by National Institute of Standards and Technology (public domain)
What's Happening Now
CAISI said DeepSeek V4 is the most capable Chinese model it has evaluated to date. The center reported that DeepSeek V4 scored 32 percent on CTF-Archive-Diamond, 74 percent on SWE-Bench Verified, 44 percent on PortBench, 74 percent on FrontierScience, 90 percent on GPQA-Diamond and 46 percent on ARC-AGI-2's semi-private dataset.
The U.S. reference systems performed unevenly across the same table, but CAISI's aggregate estimate put OpenAI GPT-5.5 at an IRT-estimated Elo of 1260, Anthropic Opus 4.6 at 999, DeepSeek V4 Pro at 800 and GPT-5.4 mini at 749. CAISI reported 95 percent confidence intervals of plus or minus 28 for DeepSeek V4 Pro and plus or minus 46 for GPT-5.4 mini.
CAISI said the eight-month lag estimate comes from an aggregate model inspired by Item Response Theory, a statistical method used in testing. The method treats models like test takers and benchmark tasks like exam questions, then estimates model capability and task difficulty from success rates.
In CAISI's appendix, the center said it used a one-parameter logistic variant of the method. CAISI said it gave equal weight to each benchmark within a domain and equal weight to each of the five domains, a design choice that keeps one large benchmark from dominating the result.
The Technical Split
The most important technical point is not that DeepSeek won or lost one leaderboard. CAISI said DeepSeek's own technical report made V4 appear roughly on par with Opus 4.6 and GPT-5.4, both described in the evaluation as recent U.S. frontier models.
CAISI reached a different result after using its own benchmark suite. The center said DeepSeek V4 showed weaker performance on some reasoning and agent-based evaluations, including ARC-AGI-2 semi-private, PortBench and CTF-Archive-Diamond.
That distinction matters because public benchmarks can be selected, overfit or contaminated. CAISI said it pre-committed to its overall benchmark suite and did not select benchmarks based on results. The center also said it reproduced DeepSeek's self-reported GPQA-Diamond result to reduce the chance that the gap came from inference or configuration errors.
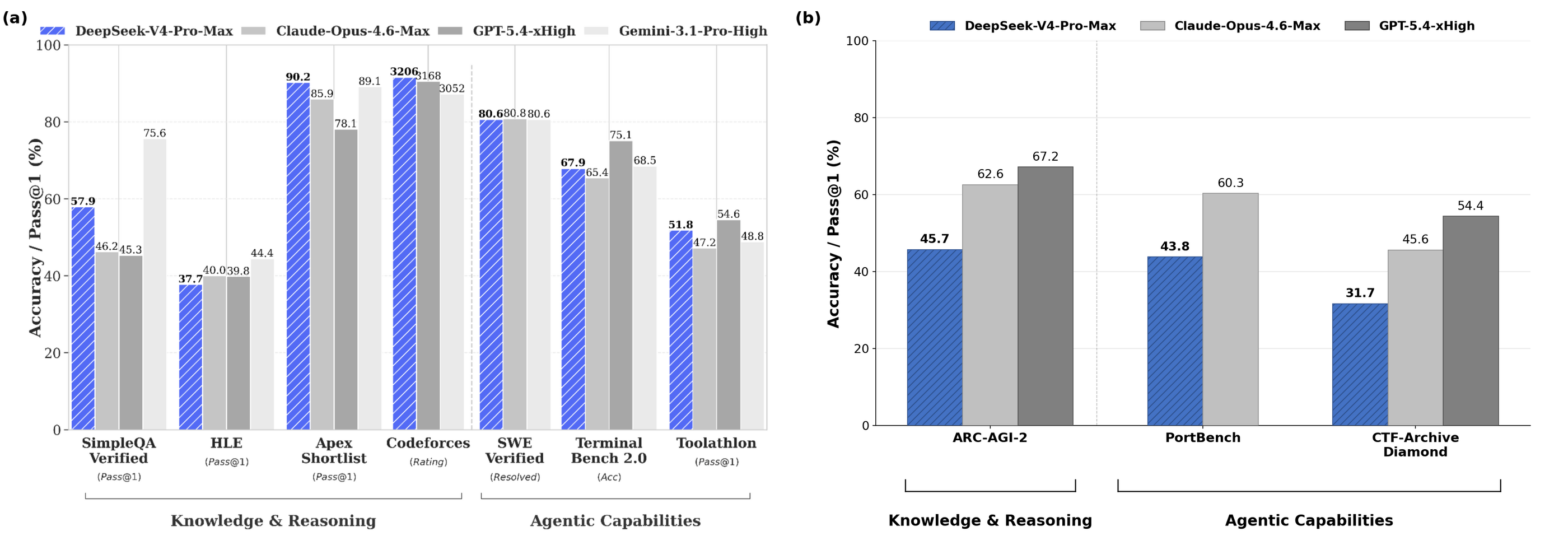 Chart by National Institute of Standards and Technology (public domain)
Chart by National Institute of Standards and Technology (public domain)
How CAISI Served The Model
CAISI said it served DeepSeek V4 from cloud-based H200 and B200 GPUs. The center said it used developer-recommended settings for context length, maximum tokens, temperature, top-p, internal reasoning preservation, system prompt and maximum thinking.
For agentic evaluations, CAISI said it used Inspect's built-in ReAct agent. The center set budgets of 1 million weighted tokens for PortBench and CTF-Archive-Diamond, and 500,000 weighted tokens for SWE-Bench Verified.
Those details separate architecture from evaluation scaffolding. The evaluation does not claim that DeepSeek V4's model architecture changed the AI frontier. It reports how one open-weight model performed under a specific serving setup, with specified agent tools, token budgets and benchmark weights.
The Cost Angle
CAISI's cost comparison used GPT-5.4 mini as the U.S. reference model after filtering out U.S. models that performed significantly worse on public benchmarks or cost significantly more per token than DeepSeek V4 Pro. CAISI said GPT-5.4 mini was the only model that met those criteria.
The center reported that DeepSeek V4 was more cost efficient on five of seven benchmark comparisons. Across the seven, DeepSeek ranged from 53 percent less expensive to 41 percent more expensive. CAISI excluded PortBench because its continuous scoring is not yet supported by the center's cost-comparison method, and excluded ARC-AGI-2 because of technical issues with the GPT-5.4 mini run.
CAISI said it used developer-reported token prices. The evaluation listed DeepSeek V4 Pro at $1.74 per 1 million uncached input tokens, $0.0145 per 1 million cached input tokens and $3.48 per 1 million output tokens. It listed GPT-5.4 mini at $0.75 per 1 million uncached input tokens, $0.075 per 1 million cached input tokens and $4.50 per 1 million output tokens.
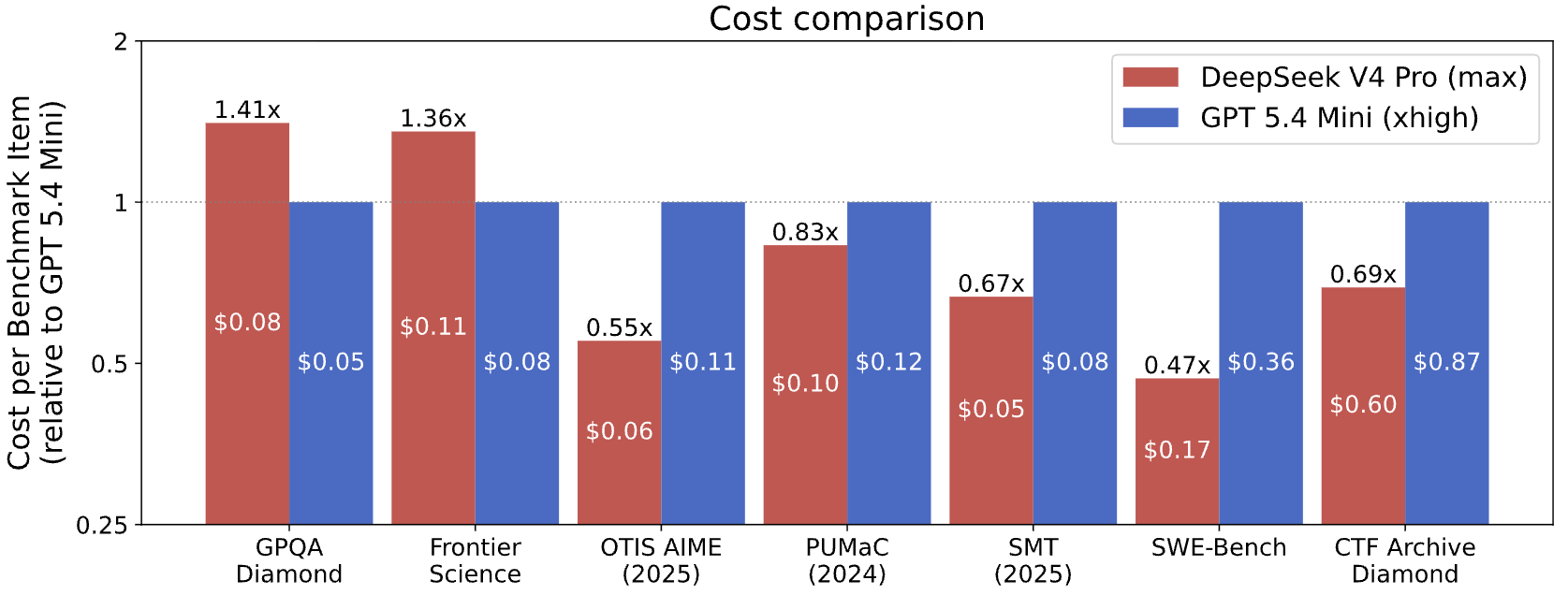 Chart by National Institute of Standards and Technology (public domain)
Chart by National Institute of Standards and Technology (public domain)
The Policy View
For national-security officials, the evaluation supports continued U.S. testing capacity. NIST says CAISI is tasked with evaluating capabilities of U.S. and adversary AI systems, foreign AI adoption and international AI competition. The DeepSeek report gives that mandate a concrete example: a foreign open-weight model tested against U.S. reference models on cyber, software, science, reasoning and math.
For open-weight advocates, the evaluation also shows why access to weights can help independent assessment. CAISI was able to serve the model on its own cloud GPUs and test it under documented settings. The White House AI Action Plan includes encouragement for open-source and open-weight AI, while also placing frontier model risk evaluation under national-security priorities.
For developers and enterprise buyers, the cost findings complicate a simple capability ranking. CAISI's own numbers show DeepSeek V4 behind the U.S. frontier, but close enough to GPT-5.4 mini in aggregate Elo that price, latency, availability and deployment rules could affect adoption decisions.
By The Numbers
- 8 months: CAISI's estimate for how far DeepSeek V4 trails leading U.S. models in aggregate capability.
- 5 domains: cyber, software engineering, natural sciences, abstract reasoning and mathematics, according to CAISI.
- 9 benchmarks: the number CAISI said it used across those domains in the DeepSeek V4 evaluation.
- 800: DeepSeek V4 Pro's IRT-estimated Elo, with a 95 percent confidence interval of plus or minus 28, according to CAISI.
- 5 of 7: the number of cost comparisons where CAISI said DeepSeek V4 was more cost efficient than GPT-5.4 mini.
What People Are Saying
"DeepSeek V4 is the most capable PRC AI model evaluated by CAISI to date." - Center for AI Standards and Innovation, May 1 evaluation
"DeepSeek V4's capability lags behind leading U.S. models by about 8 months." - Center for AI Standards and Innovation, May 1 evaluation
"DeepSeek V4 scores better on DeepSeek's self-reported evaluations than on CAISI evaluations." - Center for AI Standards and Innovation, May 1 evaluation
"Lead evaluations and assessments of capabilities of U.S. and adversary AI systems, the adoption of foreign AI systems, and the state of international AI competition." - NIST Center for AI Standards and Innovation overview
"Ensure that the U.S. Government is at the Forefront of Evaluating National Security Risks in Frontier Models" - America's AI Action Plan
The Big Picture
CAISI's DeepSeek evaluation narrows the claim but raises the stakes. The report does not say China has caught the U.S. frontier, and it does not say the U.S. lead is permanent. It says one Chinese open-weight model, tested in April on CAISI's suite, came in about eight months behind leading U.S. models while offering lower cost on most comparable tasks.
That combination is exactly why held-out testing matters. If model capability is judged only by developer-selected public benchmarks, DeepSeek V4 appears closer to current U.S. frontier systems. If it is judged by CAISI's pre-committed suite, the model looks closer to GPT-5.
The next question for policymakers and labs is whether that gap widens, narrows or shifts from capability into deployment economics. CAISI's report gives them a baseline: the U.S. frontier still leads on the center's aggregate measure, while Chinese open-weight models are now close enough and cheap enough to require direct measurement rather than assumption.


